
In his post on combining station monthly temperature series, Tamino proposes a method for calculating an “offset” for each station. This offset is intended to place the series for the stations all on at the same level. The reason that makes such an accommodation necessary is the fact that there are often missing values in a given record – sometimes for complete years at a stretch. Simple averages in such a situation can provide a distorted view of what the overall picture looks like.
In his proposed “optimal” method, Tamino suggests a procedure based on least square methods to calculate a set of coefficients for shifting a station record up or down before calculating a combined series for the set of stations. The starting point is a sum of squares (which for calculational and discussion purposes I have rewritten in a slightly different form):
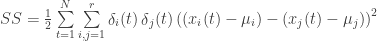
Here,
i (and j) = 1, 2, …, r, = the station identifiers for a set of r stations
t = 1, 2, …, N, = the time (i.e. year and month) of the observation
xi(t) = the observed temperature at station i at time t
µi = the offset value which is subtracted from station i
δi(t) = indicator of whether xi(t) is missing (0) or available (1)
In essence, the Sum of Squares measures the squared differences between the “adjusted” temperatures of every pair of available stations at each time with each pair weighted equally. The estimated offsets minimize this sum. The mathematically adept person will recognize that the solution for the individual µ’s is not unique, however the differences between them are. Tamino chooses to set µ1 = 0 to choose a specific solution.
All available adjusted values are averaged at each time t to form a combined temperature series. This can then be transformed into anomaly series or otherwise manipulated.
On the surface this seems like a straightforward thing to do, but, for a statistician, it leaves a lot to be desired. The principle of minimizing the given SS is not bad. Bringing the station series as close as possible to each other is a good idea. What is missing is a context – call it a mathematical model – within which one can identify and interpret the results obtained. What exactly do the results represent? What does the random variability structure of the data look like? Is the simple average of the adjusted values the best thing to do? How can one calculate error bars for the estimates (particularly if the randomness structure of the data is complicated)? Can this structure be re-stated in a different way which allows for the answer to the previous questions?
The Model
Starting with the Sum of Squares above and using some genuine ( 🙂 ) mathematical tricks, I did some “reverse engineering”. I won’t give the mathematical derivation here, although it is not all that difficult to do (although there would be a lot of equations to write out). Instead, I will give the end result:
Using similar notation to that above, the temperatures can be expressed as

τ(t) = the actual combined temperature series
µi = the offset amount by which the station differs from the combined temperatures
εi(t) = the “error” (i.e. random term) in the measurement
This is basically what might be termed a two factor Analysis of Variance. However, the reverse engineering indicates that in order to stay with achieving offsets which are the same as those which minimize Tamino’s SS, we need to weight the station temperature xi(t) with a weight proportional to
ωi(t) = the number of available stations at time t
Thus the appropriate “weighted” sum of squares to be minimized is
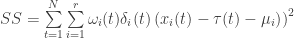
Now, this SS is minimized by exactly the same values which are calculated by Tamino’s procedure (proof, at this point in time, is left to the reader 😉 ). First, one can minimize the first SS for the estimated µ’s and then average the adjusted values to estimate the τ(t)’s. Alternatively, one can just run the appropriate procedure in R (or another program) to directly get not only the estimates of the parameters, but to get confidence error bars or to do statistical tests as well. The advantage of rewriting the problem in this fashion has been the ability to answer the questions that were raised above.
So Tamino got it right? Well, not exactly…
Plan B: A “More Optimal” Model
The model above (along with Tamino) assumes that the difference between a pair stations is a constant throughout the year. For geographical reasons, this may not be true much of the time even for stations that are relatively close. Examples of this would be a station in a coastal area compared to one farther inland. The coastal station will likely vary less during the year: cooler summers and warmer winters than the one farther inland. There can also be such differences observed due to a difference in altitude. If Tamino had looked at the residuals (temperatures minus sum of combined series and offsets) of the example series in his post , he would have noticed a pronounced annual periodicity. One might argue that this would disappear (it won’t since only the τ(t)’s would be used) if the resulting combined series is somehow anomalized, but the difficulty goes much deeper.
The reason for the necessity of this procedure is the presence of missing values. When a single offset is used, not only will a noiseless set of periodic series (with varying monthly differences) be unable to reconstruct the mean series as values are removed, but the size of the error in the estimated value will also depend on which months are missing.
Fortunately, the solution is simple. Instead of a single offset for a station, we can calculate one for each month:

m(t) = the month at time t
Our derivation above is not wasted since we can simply subdivide the time series by month and use the earlier calculation methodology to carry out the estimation procedure for each monthly series. The results are then concatenated back together to form the final combined series.
In my opinion, this is a pretty reasonable approach to use since there are other bonuses here as well. A graphical analysis of the residuals for each station can give insight about possible changes at a station whether such changes are instantaneous steps or prolonged slow increases (such as UHI) or decreases. The model can also be altered to test whether known alterations at a station have produced step changes.
I have written some scripts both from direct programming of the initial Tamino approach as well as using R’s lm procedure. The following script uses the anova model described directly above. The µ’s are centered so that the mean of all the station offsets for each month is equal to zero. If there are no missing stations at a given time, this has the effect of defining τ(t) to be the mean of all the individual temperature series.
It is possible that there may be an occasional bug in the script so please inform me if you find something amiss. If necessary, I can also tart up the script which I wrote initially for directly calculating the various estimates (both in the single offset and the multiple offset cases) to make it “turnkey” in its operation and post it. I also did not run examples of the use of the script because the post would have become too long. I will try to to run of some of these in the near future if there appears to be sufficient interest.
[Update: Further analysis has shown that this method is NOT optimal. please see Combining Stations – Plan C]
### anov.combine = Function to do monthly anova
## Input:
# ttemp = multivariate time series
## Output:
# temps = combined temperature series
# offsets = monthly offsets for each station
# residual = multivariate resuidual time series
# predicted = predicted temperatures
# Note: ttemp = predicted + residual
anov.combine = function(ttemp,anom=F) {
#function to restructure data for anova
conv.anov = function(ind.var) {
dims.ind = dim(ind.var)
response = c(ind.var)
rowvar = as.factor(c(row(ind.var)))
colvar = as.factor(c(col(ind.var)))
months = as.factor(rep(1:12,len=nrow(ind.var)))
weights = ncol(ind.var)-rowSums(is.na(ind.var))
data.frame(response=response, rowvar=rowvar, colvar=colvar, months=months, weights=weights)}
datanov = conv.anov(ttemp)
#calculate anovas by month
anovout = by(datanov, datanov$months, function(x) lm(response~0+rowvar+colvar,data=x,weights=weights))
offs = matrix(NA,12,ncol(ttemp))
temp.ts = rep(NA,nrow(ttemp))
for (i in 1:12) { testco = coef(anovout[[i]])
whch = grep("rowvar",names(testco))
temp.ts[as.numeric(substr(names(testco)[whch],7,11))] = testco[whch]-anom*testco[whch[1]]
offs[i,] = c(0,testco[grep("colvar",names(testco))])}
#center offsets and adjust time series
nr = length(temp.ts)
adj = rowMeans(offs)
offs = offs-adj
temp.ts = temp.ts + rep(adj, length=nr)
#calculate predicted and residuals for data
nc = ncol(offs)
matoff = matrix(NA,nr,nc)
for (i in 1:nc) matoff[,i] = rep(offs[,i],length=nr)
preds = c(temp.ts) + matoff
temps = ts(temp.ts)
tsp(temps) = tsp(ttemp)
colnames(offs) = colnames(ttemp)
rownames(offs) = month.abb
list(temps = temps,offsets = offs, residual = ttemp - preds, predicted=preds) }
### anomaly.calc = Function to convert temperature time series to anomalies
## Input:
# tsdat = univariate temperature time series
## Output:
# anomaly temperature series
anomaly.calc=function(tsdat,styr=1951,enyr=1980){
tsmeans = rowMeans(matrix(window(tsdat,start=c(styr,1),end=c(enyr,12)),nrow=12))
tsdat-rep(tsmeans,length=length(tsdat))}

Pingback: Roman on Methods of Combining Suface Stations « the Air Vent
Nice job. As far as improving the overlap I never considered an anomaly style monthly offset. It makes good sense, I wonder if anyone has a reason why not?
I’ll get a chance to run the script Monday probably – family stuff.
My guess is that some might have mistakenly felt that this might remove some of the “signal”. However, calculating individual station anomalies before combining does the same type of thing anyway so I don’t feel that this would really be an issue. This method also makes it unnecessary to have complete measurements in the reference baseline period for a station.
From preliminary examination of the method, I see a lot of good properties. I’ll post up more information over the next week or so.
Excellent Roman.
I’d call this “cross-calibration” myself. A method whereby one can generate enough of a profile of instrument1 and instrument2 such that there’s no discontinuity in the adjusted data regardless of which instrument is currently in use. Extensible to n instruments.
The issue I keep sticking on though is that exactly this type of procedure should be used with the only instruments we have that seem reliable for directly determining “gridcell temperature” – the satellites. Simply because of the spatial dispersion.
The question is can we use that comparison to determine compensation factors that we can then turn around and use in the pre-satellite era.
I can see how one might view this as a calibration and I have looked at it as a way of combining multiple records at a single station. However, I tend to view this as an estimation problem where the difference between the “instruments” changes in a recognizable periodic fashion. The method does not really focus on the nature of the “predicted values” of the missing observations.
This method also does not use information about the sequential time nature of the data in the estimation process and I am of the opinion that such information would be of great importance if one were trying to reconstruct the pre-satellite era “satellite” grid cell measurements.
Thanks Roman. Did you drop Tammy a note?
ha I see you did
As it is set up on my blog, WordPress sends automatic pingbacks to sites which are linked to my posts. I assume that Tamino knows about both of them.
Frankly, I don’t see him coming here for honest discussion since he would not be in complete control of what appears (or does not appear) on both sides. Who knows, I might even edit his comments and make him look foolish! 😉
The unstated principle of honor here;
Derive, Describe and Dissect the method prior to calculating the results.
Is this an incorrect attribution to your activities?
Also, how difficult would it be to run an (electrical engineering) ‘sensitivity analysis’ with this method?
(i.e., establish the sensitivity of the output to the variation of each element in the input network).
I realize this is a general method, but it is being applied to a specific input data set, with wide-ranging degrees of spatial density and recordus interruptus .
Perhaps the invariant nature of this approach is ‘casually obvious to most trivial observers’ …
However, the general topic of sensitivity metrics seems to be rarely explored in the local context of the surface station temperature records. Of course, it is also possible I exceed the bounds delineated in the prior paragraph.
I’m way out of my depth here, and have no ability to do the analysis herewith requested. I only hope that someone might address that aspect of the oftimes spatially and/or temporally sparse record of interest.
Anyway, great to see a succinct formulation of the central math. BTW, what does GISTemp look like in closed form?
The NCDC USHCNV2 generator?
RR
Not a bad way of assessing things. Derive needs to start with a model which identifies all the “moving parts” and how they relate to each other. Just coming uo with a principle and an ad hoc application cannot possible lead to a complete understanding of the process.
The equivalent of a “sensitivity analysis” here is establishing how the procedure behaves with respect to two statistical properties. The first is that the estimates of the parameters are unbiased – that you are estimating what you think you are estimating. The second is the calculation of the covariance structure structure of the estimates. I have not implemented the latter in the script yet, but it is not too difficult since it is available through the lm procedure using the vcov function applied to lm.
I finally have some time to mess with this code. I’m not an officially board certified programmer but nested functions like conv.anov are yucky. The use of the “by” function is cool though.
The model makes sense, the code makes sense, I’m comparing some different situations. You have some clever programming in there, similar in style to your anomaly calc.
This line
lm(response~0+rowvar+colvar,data=x,weights=weights)
Is it necessarily better to minimize the square of the variance rather than the mean of the variance? In other words, offset the mean of the response by month to zero rather than minimize the sum of the square.
I am pleased that you are using the script. If you find any glitches, please tell me.
I usually try to make a function as simple as possible. Using nested functions can make it easier to find programming errors and also produces a script which is easier to understand and modify. conv.anov merely restructures the data to make it suitable for the application of the lm procedure. I originally wrote it for use interactively when I was figuring out what was going on and I simply dropped it into the final function rather than integrating it into the monthly loop.
The line lm(response~0+rowvar+colvar,data=x,weights=weights) is merely a linear regression on indicator variables (a very large number of them) so what is happening is that least squares determines the estimation procedure. The “0” suppresses the constant term and therefore allows me to pull out the combined series without a bit of extra work otherwise needed. The weights are very important in ensuring that the estimated values are unbiased. If all stations are present at each time point, then this the combined series will simply be the average of all the temperatures at each time (as one would expect).
I understand, and to me it was clever way to handle the series. What I’m scratching my head about is whether it’s better to simply take the mean of the points which exist in both series for a difference based offset rather than what amounts to a least squares of the difference calculation.
The problem is that when more than two series are involved, the overlap time period, say between series 1 and series 2, is not necessarily the same as between series 1 and series 3. Thus, calculating, as per your suggestion, would give me two (probably different) offsets for series 1. Simple averaging of these to create a single offset would often not be in order since different numbers of observations may be involved in the two overlaps (and what do you do in the situation when the two overlap intervals themselves overlap with all three simultaneously present part of the time).
Rather than hunting for an ad hoc solution, it is preferable to use a procedure that has known optimality and unbiasedness properties. Statisticians have been dealing with such situations for years. This one is not that complicated and we can get all of the information needed out of it.
I see. It makes sense. What I did in the Antarctic was to start from the first series with data in it and work forward the first station (or two) had zero offset.
I plan to integrate your method into the full gridded algorithm after messing around with it some more. It’s exciting becaue I think you’ve improved on the combination of series over what is standard.
The drawback of a sequential method of this type is that very often the final result depends on the order that you choose to for entering the stations. Often, one starts by picking the longest records and subsequently ordering them by decreasing record length. This is not necessarily optimum as the error propagation is typically not easily calculated for the method, thereby making accurate error bars difficult to determine.
A method which simultaneously includes all the stations will be easier to work with.
Since I was only looking for trend, the order was determined by the start date of each new station. The goal was to have as little step as could be optimally produced.
One additional criteria I imposed was the use of only X initial months of data. The idea was to allow some divergence for long term weather patterns. It didn’t make much difference in the antarctic though. I imagine if each gridcell is processed separately by this method, there wouldn’t be much difference either.
If we didn’t have to work today, I would be working more on this. Too bad Exxon isn’t footing the bill.
I wonder if you have any preference as to how the gridcells are integrated.
Should say — I wonder if you have any preference as to how the gridcells are combined.
My comment went out of order. Sorry.
So I’m your first troll, spammin’ the blog.
I ran skikda by itself through the algorithm. There are 3 time series which are IMO from the same instrument. The getstation function from my post recognizes the similarity and takes a mean. The difference between the two is only 0.007 C/Decade though. I believe the getstation function is more correct in this single case but the difference is not big. The tradeoff in comparison to your single step algorithm is difficult to justify.
I’m going to run a gridded version tonight, don’t know if I’ll finish.
Crashed on a series with no overlap. I’ll work it out but it will be tomorrow now.
Pingback: Comparing Single and Monthly Offsets « Statistics and Other Things
Pingback: Combining Stations (Plan C) « Statistics and Other Things
Pingback: GHCN Global Temperatures – Compiled Using Offset Anomalies « the Air Vent
Pingback: Calculating global temperature | Watts Up With That?
Pingback: Gridded Global Temperature « the Air Vent
Pingback: The First Difference Method « Climate Audit
Pingback: Proxy Hammer « the Air Vent
Niezwykle wartościowy tekst, zalecam ludziom
Hi to all, for the reason that I am really keen of reading this weblog’s post to be updated regularly.
It carries good stuff.
If you are going for best contents like myself, simply go to see this web page
all the time since it provides feature contents, thanks
This is the perfect blog for everyone who would like to understand this
topic. You know a whole lot its almost hard to argue with you (not
that I really will need to…HaHa). You certainly put a fresh spin on a topic which has been discussed for years.
Excellent stuff, just excellent!
Pingback: Calculating global temperature anomaly | Watts Up With That?
Pingback: Calculating global temperature anomaly |
Pingback: Calculating global temperature anomaly – Climate Collections
Pingback: ≫ Calculating global temperature • Watts Up With That?