
Over the last month or two, I have been looking at the response by Schmidt, Mann, and Rutherford to McShane and Wyner’s paper on the hockey stick. In the process, I took a closer look at the total least squares (error –in-variables or EIV) regression procedure which is an integral part of the methodology used by the hockey time in their paleo reconstructions. Some of what I found surprised me.
A brief explanation of the difference between ordinary least squares (OLS) and EIV is in order. Some further information can be found on the Wiki Error-in-Variables and Total least squares pages. We will first look at the case where there is a single predictor.
Univariate Case
The OLS model for predicting a response Y from a predictor X through a linear relationship looks like:

α and β are the intercept and the slope of the relationship, e is the “random error” in the response variable due to sampling and/or other considerations and n is the sample size. The model is fitted by choosing the linear coefficients which minimize the sum of the squared errors (which is also consistent with maximum likelihood estimation for a Normally distributed response:
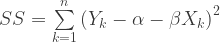
The problem is easily solved by using matrix algebra and estimation of uncertainties in the coefficients is relatively trivial.
EIV regression attempts to solve the problem when there may also be “errors”, f, in the predictors themselves:

The f-errors are usually assumed to be independent of the e-errors and the estimation of all the parameters is done by minimizing a somewhat different looking expression:

under the condition
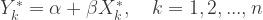
X* and Y* (often called scores) are the unknown actual values of X and Y. The minimization problem can be recognized as calculating the minimum total of the perpendicular squared distances from the data points to a line which contains the estimated scores. Mathematically, the problem of calculating the estimated coefficients of the line can be solved by using a principal components calculation on the data. It should be noted that the data (predictors and responses should each be centered at zero beforehand.
The following graphs illustrate the difference in the two approaches:

What could be better, you ask. Well, all is not what it may seem at first glance.
First, you might have noticed that the orange lines connecting the data to the scores in the EIV plot are all parallel. The adept reader can see from considerations of similar triangles that the ratio of the estimated errors, e and f (the green lines plotted for one of the sample points), is a constant equal to minus one times the slope coefficient (or one over that coefficient dependent on which is the numerator term). The claim that somehow this regression properly takes into account the error uncertainty of the predictors seems spurious at best.
The second and considerably more important problematic feature is that, as the total-least squares page of Wiki linked above states: “total least squares does not have the property of units-invariance (it is not scale invariant).” Simply put, if you rescale a variable (or express it in different units), you will NOT get the same result as for the unscaled case. Thus, if we are doing a paleo reconstruction and we decide to calibrate to temperature anomalies as F’s rather than C’s, we will end up with a different reconstruction. How much different will depend on the details of the data. However, the point is that we can get two different answers simple by using different units in our analysis. Since all sorts of rescaling can be done on the proxies, the end result is subject to the choices made.
To illustrate this point, we use the data from the example above. The Y variable is multiplied by a scale factor ranging from .1 to 20. The new slope is calculated and divided by the old EIV slope which has also been scaled by the same factor.

If the procedure was invariant under scaling (as OLS is), then the result should be equal to unity in all cases. Instead, one can see that for scale factors close to zero, the EIV behaves basically like ordinary OLS regression . As the scale factor increases, the result (after unscaling) looks like 1/the OLS slope with the X and Y variables switched.
However, that is not the end of the story. What happens if both X and Y are each scaled to have standard deviation 1? This surprised me somewhat. The slope can only take either +1 or -1 (Except for some cases where the data form an exactly symmetric pattern for which ALL slopes produce exactly the same SS).
In effect, this would imply that, after unscaling , the EIV calculated slope = sd(Y) / sd(X). To a statistician, this would be very disconcerting since this slope is not determined in any way shape or form by any existing relationship between X and Y – this is the answer when the data points are in an exactly straight line or when they are uncorrelated. It is not affected by sample size so clearly large sample convergence results would not be applicable. On the other hand, the OLS slope = Corr(X,Y) * sd(Y) / sd(X) for the same case so that this criticism would not apply to that result.
Multilinear Case
So far we have only dealt with the univariate case. Perhaps if there are more predictors, this would alleviate the problems we have seen here. All sorts of comparisons are possible, but to shorten the post, we will only look at the effect of rescaling the all of the variables to unit variance.
Using R, we generate a sample of 5 predictors and a single response variable with 20000 values each. The variables are generated “independently” (subject to the limits of a random number generator). We calculate the slope coefficients for both the straight OLS regression and also for EIV/TLS:
| Variable | OLS Reg | EIV-TLS |
| X1 | 0.005969581 | 1.9253757 |
| X2 | 0.010657532 | 1.8661962 |
| X3 | -0.005656248 | 3.7607298 |
| X4 | -0.003537972 | 0.6509362 |
| X5 | 0.003616522 | 4.4236177 |
All of the theoretical coefficients are supposed to be zero and with 20000 observations, the difference should not be large. In fact 95% confidence intervals for the OLS coefficients all contain the value 0. However, the EIV result is completely out to lunch. The response Y must be scaled down by about 20%, to have all of the EIV coefficients become small enough to be inside the 95% CIs calculated by the OLS procedure.
EIV on Simulated Proxy Data
We give one more example of what the effect of applying EIV in the paleo environment can be.
As I mentioned earlier, I have been looking at the response by Gavin and crew to the M-W paper. In their response, the authors use artificial proxy data to compare their EIV construct to other methods. Two different climate models are used to generate a “temperature series” and proxies (which have auto-regressive errors) are provided. I took the CSM model (time frame used 850 to 1980) with 59 proxy sequences as the data. An EIV fit with these 59 predictors was carried out using the calibration period 1856 to 1980. A simple reconstruction was calculated from these coefficients for the entire time range.
This reconstruction was done for each of the three cases: (i) Temperature anomalies in C, (ii) Temperature anomalies in F, and (iii) Temperature anomalies scaled to unit variance during the calibration period. The following plots represent the difference in the resulting reconstructions: (i) – (ii) and (i) – (iii):

The differences here are non-trivial. I realize that is not a reproduction of the total method used by the Mann team. However, the EIV methodology is central to the current spate of their reconstructions so some effect must be there. How strong is it? I don’t know – maybe they can calculate the Fahrenheit version for us so we can all see it. Surely, you would think that they would be aware of all the features of a statistical method before deciding to use it. Maybe I missed their discussion of it.
A script for running the above analysis is available here (the file is labeled .doc, but it is a simple text file). Save it and load into R directly: Reivpost

RomanM
You are quite right to draw attention to the peculiarities of TLS regression. It should, however, be borne in mind that what Mann and his co-workers use is Truncated TLS (TTLS), where only a small number of EOFs/PCs are retained. Where, as is common in climate science, the dataset is ill-conditioned, basic TLS is unsuitable. By discarding all but the lowest few EOFs, reasonably stable regression coefficients and predictions can be achieved.
As you say, TLS is not scale invariant, nor of course is TTLS. In RegEM, as used by Mann etc., all the variables are scaled to unit standard deviation, but I have not found TTLS to be a particularly satisfactory regression method for RegEM. When RyanO and I were experimenting with TTLS RegEM on the Antartica stations dataset, we found that the resulting infilled data varied very considerably depending on the truncation parameter (number of EOFs retained).
Switching to ridge regression led to much more stable RegEM results, which moreover were little affected by the scaling of the variables. Ridge regression can also be considered an EIV method, in that it takes account of errors in the predictor (independent) variables as well as in the predictand (dependent) variables.
I understand that what I have looked at here is not exactly what is done in the RegEM application of EIV regression. I was more interested in examining the vagaries of the procedure itself without having to worry about additional choices made in the reconstructions.
The points I was trying to make are:
The claim that EIV properly takes into account the uncertainty in the predictor variables is a myth. In order to do that, one needs to have prior knowledge of the relative “error” in each of the variables and then use a weighted version of the EIV procedure (for which I have cobbled up a function but have not posted it up). This may apply to the Regem application as well.
The sensitivity of the procedure to changes in the scaling and the mathematical instability of the procedure when applied to variables scaled to equal variability. There is nothing inherently more correct or less correct about doing an analysis in degrees C or degrees F yet, the results are different, sometimes pretty drastically. To choose this procedure for use in the Regem context is at best questionable.
The problem exists whether you have one or two predictors or a large collection of them. Adding variables (or more observations) into the mix does not necessarily improve the situation.
I dislike justifications which state that a result “was little affected by the …”. Unless NO other techniques are available for use in a situation, ones that have obvious problems should be avoided.
In this case, IMHO, the problem stems from initially stating the model backwards: Temperature is (unphysically) a function of the proxies, rather than the opposite: the proxies are a function of temperature.
Mann’s approach imposes all sorts of requirements on the mathematics of the situation: TLS and TTLS require complete observations – each predictor must be present at all times or be infilled, there can be rank deficiencies when you have too many predictors so ad hoc “regularization” is needed, the danger of overfitting in the calibration period is omnipresent and the method has its serious technical drawbacks.
Properly applied “inverse calibration” applied in an EM fashion offers much more promise for solving the reconstruction problem and does not suffer from many of the failings listed above. But that is a topic for another thread…
Anyway, just for fun, I would like to see how Mann’s stick might change when doing the analysis in C’s instead of F’s. 🙂
“The claim that EIV properly takes into account the uncertainty in the predictor variables is a myth. In order to do that, one needs to have prior knowledge of the relative “error” in each of the variables.”
I entirely agree.
I also agree that inverse calibration seems much more appropriate than RegEM for the proxy reconstruction problems that Mann has mainly worked with, but I think not only because of the direction of physical causation. The proxies have much lower S/N ratios than the instrumental data (treating the signal as variance that is common to proxy and isntrumental data), and I think high and unquantified noise in the predictor variables causes more problems for regression than high and unquantified noise in the predicatand variables.
Because RegEM scales all variables to unit standard deviation (and rescales at the end), I think Mann would have got the same results whatever units he expressed temperature in.
As a another concern, the RegEM regression is sensitive to the number of copies of a variable that the data it works on contains. If you include four copies of a variable, that has the same effect as if a single copy were used but (unlike the remaining variables) is only scaled down to a standard deviation of 2, giving that variable more weight in the regression. Many of Mann’s proxy series are similar to each other, of course.
Scaling all the variables to unit sd and then tossing an EIV-style regression procedure (regularized or not) sounds like one of the poorer approaches to take.
Why would one include multiple copies of a variable in the data?
I agree, it is not a very good approach.
I once tried including multiple copies of a variable in data fed to RegEM to see what effect it had on the resulting regressions and infilling. Quite a lot, in some cases. But my point was that paleoclimate reconstructions may involve over 1000 proxy variables, many of which may be very similar to each other (highly co-linear), so in effect one is including multiple copies of almost the same data, and thereby giving it greater weighting in the regressions.
Pingback: EIV/TLS Regression – Why Use It? « the Air Vent
Dear Professor M
You have a cool blog here! I’m a former student of yours and I’m desperately trying to get in touch with you. I would be very thankful if you contacted me at ######@rocketmail.com as soon as it’s possible for you.
I’m very much hoping to hearing back from you.
Regards,
J
Hi Dr. M,
I was looking over your “hammer” approach to combining stations and I was wondering whether using yearly data would eliminate the need for correcting the seasonal cycle. Using yearly raw data I was doing a comparison of RSM, FDM, CAM and an adapted version of Tamino’s (all using yearly data) and I was wondering whether your version would be inherently different than Tamino’s if using yearly?
Robert, I will reply to your comment in a more appropriate thread .
Pingback: The Two-and-One-Half PC Solution | Statistics and Other Things
Pingback: Climate Blog and News Recap: 2011 02 19 « The Whiteboard
I’m not exactly sure how the whole paleo reconstruction process works then.
Why do they not just take different proxies, convert them into temperature values through validation with the instrumental record, and then treat them the same we would station values and hammer them out.
If that isn’t how they do it, how do they do it? Do they really run multiple regression across a series of proxies compared to the instrumental record and then extend it back? Sorry if I’m behind the times.
You need to learn more about the difficulties of the paleo reconstruction process. The answer is not so simple and it would take a full chapter in a book to explain all of the ins-and-out of the different methods that can be used.
What is meant by the statement “take different proxies, convert them into temperature values through validation with the instrumental record“? One needs to define how the temperatures might mathematically relate (different ways are possible) to temperatures (and to which specific temperature series). One needs to estimate the parameters involved and using the derived relationship, “convert” them into estimated temperature values (along with estimated error bounds), and “validate” by convincing others that the relationship is not spurious.
The avenues available depend on whether there is a single proxy series (e.g., an ice core) or whether there are multiple proxies at a single location (e.g., trees at a particular location) or a variety of proxies (not necessarily of the same type) scattered over a wide set of localities. How would you “hammer out” proxies from three or four sites and what would you claim that the hammered result is estimating?
Some methods do indeed use multiple regression (running the risk of overfitting), others may use “inverse” regression (possible bias if a single proxy is used) while some may simply combine the proxies into a single series (giving spurious proxies an equal weight in forming the series) which can then be scaled and centered to match an existing temperature record.
“Converting them into temperatures” in a credible fashion is not a trivial exercise.
Dear Sir;
I noticed this ‘interesting’ discussion of a statistical method (Hurst-Kolmogorov) that I hadn’t previously been ~’aware’ (to the extent that any non-statistician can be truly aware…)
Click to access Koutsoyiannis.pdf
What is your opinion of the relevance of this school of thought? Does ‘R’ readily support the evaluation of HK statistical measures?
Did I abuse any keyword jargon herewith?
BTW, I see that I still owe you an geophysical answer to the question of some station locations.
I have dayjob impingement issues…
Thanks,
RR
Thank you Ruhroh, that is a very interesting presentation!
So, in nature, short term variability is higher and long term variability is lower than a simple random process would predict? If therefore we wish to be able to claim, with the alarmists: “It is a record” than Gaia is on our side, even though the long term trend would not support such claims generally?
Here is some discussion of TLS from the thread “Un-Muddying the Waters” (11/7/11) over on CA. It’s more OT over here.
Hu McCulloch
Posted Nov 10, 2011 at 3:55 PM | Permalink | Reply
Roman —
I can’t say that I have ever actually used TLS, but from reading up some on it after discussions here on CA, it sounds to me like a very reasonable way to handle the errors-in-variables problem.
However, the elementary treatments I have seen just assume that the variances of all the errors are equal. In fact, they ordinarily wouldn’t be equal, and in order for the method to be identified, you have to know what their relative size is (or what the absolute size is on one side). Then you can rescale the variables so that the errors are equal, and use the elementary method. This gives you “y on x” in the limit when you know that x has no measurement error, and “x on y” in the limit where you know that x has measurement error but there are no regression errors.
Is there a standard way to compute standard errors or CI’s for the coefficients in TLS? I haven’t seen that. (Since the measurement-error-only case corresponds to the calibration problem, the CI’s may be nonstandard).
Another issue that is glossed over is the intercept term — most regressions include an intercept, which is the coefficient on a unit “regressor”. However, there is never any measurement error on unity, so it has to be handled differently. A quick fix-up is just to subtract the means from all variables, which forces the regression through the origin, and then to shift it to pass through the variable means instead. But then we still need an estimate of the uncertainty of the restored intercept term.
The widely used econometrics package EViews doesn’t seem to have TLS. An Ivo Petras has contributed a TLS package to Matlab File Exchange. It may work, but as such it has no Matlab endorsement. (I recently found a very helpful program to solve Nash Equilibria there, but it only worked after I corrected two bugs.)
Do you approve of TLS?
RomanM
Posted Nov. 10, 2011 at 5:41 PM | Permalink | Reply
Hu, basically you have it right.
The usual approach is to center all of the variables involved at zero (the line can be moved by de-centering the result later) and as Steve says an svd procedure applied to estimate the coefficients. In the case of two variables, there is an explicit solution. Inference on the result would be difficult and resampling or asymptotic large sample results would likely be the only type of inferential methodology available. I have not bothered to research what these methods might be.
I have some real concerns that the methods don’t really properly take into account the individual “errors” for the predictors or the responses. For each observation, there is in effect a single “residual value” which is apportioned to each of the variables (in exactly the same proportions for each observation) where the apportioning is determined by the fitted line (or plane as the case may be). I wrote up some criticism of the procedure at my blog a year ago.
If you want a simple R function to do TLS, you can try this:
reg.orth = function(ymat, xmat) {
nx = NCOL(xmat); ny = NCOL(ymat)
tmat = cbind(xmat,ymat)
mat.svd = svd(tmat)
coes = -mat.svd$v[1:nx,(nx+1):(nx+ny)] %*% solve(mat.svd$v[(nx+1):(nx+ny),(nx+1):(nx+ny)])
pred = xmat %*% coes
list(coefs=coes,pred=pred)}
ymat and xmat are matrices containing the response variables and the predictor variables, respectively. They should be decentered before use. The output is the regression coefficients and the predicted values for ymat. The residuals can be calculated by subtracting the latter from ymat. In the case of a single variable for each, the coefficient is the slope and the predicted values form a straight line.
Do I “approve” of the procedure? I guess there are probably some uses, but IMHO, I don’t see that it really handles the problem that all of the variables can contain uncertainty in any reasonable fashion.
Hu McCulloch
Posted Nov 11, 2011 at 11:49 AM | Permalink | Reply
Thanks for the link to your blog page, Roman. Since this is getting OT here, we should move this discussion there.
But as you note in one of your comments on your page, the variables must be scaled so that their errors have equal variance before running standard TLS. If this is not done, measuring temperature in F rather than C changes the results, and equalizing the variances of the variables themselves can give absurd results.
More over there later…
Roman —
I’ve now had a chance to look at TLS a little, and have even implemented a simple program in Matlab.
Although you — and much of the climate literature — use “EIV” and “TLS” interchangeably, I view EIV (Errors in Variables) as a generic problem, and TLS (Total LS) as merely one proposed solution.
Although TLS sounds good on paper, in practice it is almost never useful, since it requires knowing the relative variances of the two errors e and f.
I was at first concerned that TLS might not even be consistent, since if one had scaled the variables so that e and f had equal variance, and then were to go back and re-estimate the variances of e and f from the TLS regression residuals, the ratio of the variances would equal the slope of the line, as shown in your figure 2 above, rather than unity. But in simulations I did with sample size 100, 1000, and 100,000, the estimate of the slope converged on the true value for several combinations of parameters, so this apparently is not a problem. Wikipedia and a helpful 1996 article by P. de Groen I found online do not mention the issue of consistency, so a proof of this could be a nice paper for someone (not me!).
A far more useful solution to the EIV problem is what might be called Adjusted OLS: As is well known (see Wiki or Pindyck and Rubinfeld’s text), the standard OLS estimator
bOLS = cov(x,y)/var(x)
has plim
beta var(x*)/var(x).
But this implies that the adjusted OLS estimator
bADJ = bOLS var(x)/var(x*) = cov(x,y)/(var(x) – var(f))
is consistent. The multivariate case is similar, I believe. For some reason, neither Wiki nor deGroen nor P&R suggest this obvious adjustment.
In climate data, for example, it is common to use a temperature series like HadCRU as the explanatory variable (when properly using CCE to calibrate a proxy, for example). But CRU admits this has a measurement standard errror of .10 (in 1850) to .025 (since 1950), or about .05 on average. Meanwhile, the series itself has risen by about 1 dC since it started, so that it has a variance of about 0.1. This makes bOLS low by a factor of about 0.975, so that bADJ = bOLS * 1.026. Not enough to worry about, as it turns out, but worth checking. (CRU may in fact be overstating the precision of its temperature indices, but that is another matter.)
If var(x) turns out to be less than var(f), that just means that whatever variation there is in x is just noise, and one shouldn’t even bother running the regression.
Another use for Adjusted OLS is in 2 Stage LS IV estimation — the first stage regression gives a noisy but exogenous proxy for the endogenous regressor(s), but it also gives an estimate of the variance of the noise. The second stage regression then can be boosted with bADJ to reduce its finite sample bias. (In IV, the first stage noise goes to zero as the sample size gets infinite, so that 2SLS is consistent despite the EIV bias. But still it’s worth removing as much of the finite sample bias as possible with bADJ, particularly when the instruments are weak, as is often the case.)
In the limit when var(e) = 0, so that there is measurement error in x but no regression error in y, the natural solution is Reverse Regression — regress x on y and invert. This is the limit TLS yields, as shown in your third graph. But although bADJ has the same plim, it will give a different actual value.
Wayne Fuller has a relatively recent book on Errors in Variables problems which I suspect may use bADJ, but I only took a cursory look at it some time ago.
Someone (not me) should work out the theory of standard errors for the Adjusted OLS and TLS estimators.
Hu, your point on the difference in usage of the two terms EIV and TLS is well taken. I will start making that distinction in the future.
I have looked at the situation further and did some more analysis which seemed to add further insight in regards to some of your other points:
I believe the problems with TLS to go deeper than that. If the relative variances are known, TLS can be applied after weighting the the SS components in the head post inversely to the variances of the e and f “errors” (thus reducing the problem to the equal variance case). However, the residuals for e and f are still perfectly linearly correlated although the ratio between them is changed to take the weighting into account.
After reading your comments, I also tried a sequential reweighted LS approach as well. At each step, the variances of e and f were re-estimated and the regression repeated using the new weights. However, all of the cases I tried converged to the end result of a LS where the variable with the higher variance has its error term reduced to zero variability. I also looked very briefly at using maximum likelihood with normally distributed errors, but it wasn’t clear that this would produce any better results.
With regard to the consistency of the parameter estimates, my gut feeling would be that in most cases the results would be consistent although there might be demonstrable bias in the parameters (that converged to zero as the sample size increased). Where it could be bothersome is in the case that X and Y are uncorrelated with approximately equal variability. However, |I am just guessing on this aspect and it could be wrong.
The possible use of Adjusted OLS is intriguing, but I would need to do some reading to say more about that.
Getting insight on the behavior of the estimates and their standard errors is made more difficult because the mechanics of the calculation involve portions of the principal components of the variables – in the multivariate case particularly. Something that might make it easier to comprehend is to do the calculations recursively and examine what happens in that process. I wrote a short program for this:
tls.alt = function(yvec,xvec,wts = c(1,1),tol=1E-6) { #wts = (y-variable weight, x-variable weight) # typically weights would be 1/ variable variance #variables do not have to be centered dif = tol+1 ywt = wts[1]; xwt = wts[2] newx = xvec while (dif>tol) { lastx = newx regco = coef(lm(yvec~newx)) newx = (ywt*regco[2]*(yvec-regco[1]) + xwt*xvec)/(xwt+ ywt*regco[2]^2) dif = max(abs(newx-lastx),na.rm=T)} yscore = regco[1]+regco[2]*newx xres = xvec-newx yres = yvec-yscore xss = sum(xres^2, na.rm=T) yss = sum(yres^2, na.rm=T) list(coefs=regco,yscore = yscore, xscore = newx, xresid =xres,yresid=yres,xss=xss,yss=yss)}How did you do this? Originally I was hoping to iteratively estimate the variance of e from the TLS residuals, starting from knowledge of var(f) and an initial guess of var(e) (say from OLS of y on x). But then I realized that TLS does not give back the true relative variance of f and e, unless the slope happens to be +/- 1 which would only be by accident.
Although TLS is ML-motivated, it does not necessarily have the nice properties of ML. ML is consistent if a fixed number of parameters are being estimated with an increasing number of observations. But in TLS the number of unknowns increases 1-for-1 with the number of observations, so that x* and y* are not consistently estimated. It appears that as a consequence, the variance ratio is not consistently estimated by the residuals, even though the slope appears to be consistently estimated (from my limited simulations).
Please e-mail me (and the gang) if and when you add to this interesting discussion, as it proceeds rather slowly.
Sorry for the delayed response, Hu.
The method I tried to use was adapted from my tls.alt function above, but re-weighting the variables with the estimated variances from the previous step. However, the re-weights had the effect of stalling the coefficients on the OLS values and sending one of the weights off to infinity.
I think that your comments on the number of unknowns in TLS exceeding the amount of information in the observations is particularly on target here. As is, that approach seems to be a bit of a dead end.
Here’s my 3-line Matlab script to compute univariate TLS on pre-centered data that has been normalized so that the variances of e and f are equal:
% TLS0
% univariate TLS with pre-centered and pre-normalized data
% (zero in name indicates restricted problem)
% x, y ~ n x 1
% x = xstar + f, y = ystar + e
% ystar = beta * xstar, var(f) + var(e) = min.
% x and y have been pre-normalized so that var(e) = var(f)
% by Hu McCulloch 1/28/12, after P. de Groen, “An Introduction to
% Total Least Squares,” Nieuw Archief voor Wiskunde, 1996, 14:237-53,
% http://www.freescience.info
function [beta] = TLS0(x, y)
B = [x y];
[U, S, V] = svd(B, ‘econ’); % B*V = U*S, S is 2×2, V is 2×2
beta = -V(1,2)/V(2,2); % This correctly gives inf if V(2,2) = 0.
end
% xstar and ystar are in U somewhere, but I’m not certain how to
% recover them.
return
It’s not really necessary to define “B”, but I’ve included it for clarity.
Catching up slowly, Statistical Regression with Measurement Error
seems to be a good book to start. If the ratio of the _error_ variances is known, the _data_ can be scaled so that this ratio becomes one. Then the maximum likelihood solution of the normal ME (measurement error) regression is orthogonal regression (p.9).
For the calibration problem the book offers interesting reference for comparing ICE, CCE and ME,
C-L. Cheng and C-L. Tsai (1994). “The comparisons of three different linear calibration estimators in measurement error models.”
It is listed in here, http://www.stat.sinica.edu.tw/clcheng/index.htm but it is unpublished manuscript…
In my opinion CCE is the only way to go with proxies. ICE implies structural model ( we know a lot about past temperatures prior to looking at proxies ), and for orthogonal regression the assumption seems to be that we know the ratio of the error variances prior to looking at proxies. But I’m quite unfamiliar with this topic, so I might be wrong.
UC —
Thanks! I couldn’t find the Kendall series book you cite, but OSU has a volume with an article on this by the same Cheng and Van Ness that looks similar. I’ll take a look at it — and have requested Fuller’s book on Measurement Error problems as well. (It’s from the 80’s – older than I thought.)
I agree that CCE is ordinarily the way to go with proxies, since the regression error is much bigger than the measurement error in the instrumental temperature series (we hope!). But TLS sounds good on paper and is popular with climate people, so it’s good to figure out why it does or doesn’t help.
According to Wiki, the emminent economist Paul Samuelson was enthusiastic about TLS back in the 1940s when he was an eager-beaver grad student. But now the econometric texts don’t even mention it.
I’ve now had a chance to read at least the first few sections of Wayne Fuller’s 1987 book Measurement Error Models. Also relevant are Carroll and Ruppert, “The Use and Misuse of Orthogonal Regression in Linear Errors-in-Variables Models,” American Statistician 1996, 50: 1-6 (CR) and Ammann, Genton and Li, “Technical Note: Correcting for signal attenuation from noisy proxy data in climate reconstructions,” Climate of the Past 2010, 6:273-79 (AGL). All three discuss both what I call “Adjusted Least Squares” above, as well as TLS.
Fuller is the standard reference and derives what I called the Adjusted Least Squares estimator in his sections 1.1 and 1.2. He awkwardly calls it “least squares corrected for attentuation, but following AGL it would be appropriate to call it “Attenuation-Corrected LS”, or ACLS. (In fact AGL call it ACOLS, but if OLS is modified, it is no longer ordinary, so the O becomes unnecessary or even incorrect.)
Then in his section 1.3, Fuller derives the TLS estimator. Unfortunately he does not mention either term, “TLS” or “Orthogonal LS”. He provides three different derivations of the formula, but unfortunately does not include the nice SVD approach. He shows that it is consistent (p. 32), and gives its asymptotic covariance matrix. On p. 47, he discusses a method for obtaining confidence intervals that I haven’t digested, but which sounds similar to the classical Fieller confidence sets for CCE, because “The confidence sets constructed by the methods of this section will not always be a single interval and can be the whole line.”
AGL embrace ACLS as a solution to the inconsistency of ICE (Inverse Calibration Estimation) when estimating past temperatures from noisy proxies. In doing so, they invent what might be called “Backward LS” (BLS).
They have a case in which their “X” is a noisy proxy (such as an isotope ratio), and “Y” is instrumental temperature, so that var(f) is important but var(e) is nearly 0 and the usual roles of “X” and “Y” are reversed. Instead of just regressing “X” on “Y” and inverting to reconstruct Y from X as in CCE (Classical Calibration Estimation), they regress “Y” on “X” and then correct this ICE estimate for attenuation using ACLS. In order to obtain an estimate of var(f) they do regress X on Y and compute the variance of the residuals, but otherwise discard the consistent CCE estimate of the slope.
Simulations indicate that AGL’s BLS substantially mis-corrects for attenuation in the slope (and therefore also its reciprocal) when the significance of the slope is marginal (expected t = 2), if the standard unbiased estimator s^2 of the X on Y regression error variance is used to estimate var(f) and the adjustment factor is taken as infinity whenever var(x) < var(f). But surprisingly, BLS appears to exactly give the CCE estimator of the slope (and therefore the OLS estimator of its reciprocal) when the Mean Squared Error (dividing by n instead of n-2) is used to estimate var(f). So at best it has no advantage over CCE and at worst it is a lot worse.
AGL propose a further modification of ACLS when both types of error are present, using a cross-validation procedure involving only the X and Y data to estimate their "k". However, this can't be valid, since as Fuller points out, the slope is not identified unless there is some external information about the absolute or relative size of the two types of error. If var(e) (in this case the temperature measurement error) is known externally, it can just be used with ACLS to modify the CCE estimator as I noted in an earlier comment here.
Dear Dr.;
I have a lay question, triggered by the Gergis Significance thread at CA.
If they are (at the end of the last blackboard) going to merely weight the various series in the big weighted summation, why do they bother to pre-select the ones that they analyze? The proxies with no contribution would just get a low weight, right?
Maybe there is some problem of the ‘unhelpful’ proxy series diluting the ‘significance’ of the outcome? Or what?
I am having trouble guessing why they bother to toss (or ‘screen out’ ) unpopular series ‘a priori’.
Please forgive my ‘lay’ usage of words which have very specific meanings in your field.
Maybe you will leave some breadcrumbs in your embedded commentary over at CA.
TIA
RR aka AC
Greetings,
I have run the attached script in R in order to walk through the comparison between OLS and EIV/TLS. I’ve learned a lot about R in a short period of time. The claim is made that the EIV/TLS data is “out to lunch”, but what about the y-intercept? How does the calcx.tls output the intercept. Also, aren’t the associated p-values and coefficient signs more important than the coefficient itself, where it simply reflects the units of each parameter? Lastly, I can’t seem to find much info on calcx.tls function. Any web/thread leads would be helpful. Thanks.
-EC
With regard to the y-intercept, there is no y-intercept. In order to do the regression properly, you need to center all of the variables at zero. Then after the regression has been calculated, the subtracted means and regression coefficients will provide the intercept. The calcx.tls function was written by myself to carry out the calculations. Depending on how much math you know, you might look here to see what needs to be done for the procedure. For the two variable case, you can try Deming regression function.
I am not sure why you think that “the associated p-values and coefficient signs more important than the coefficient itself”. Generally, the coefficients (and their signs) are quite important because they carry information about the type and magnitude of the relationship. The p-values are important in determining the uncertainty level of the estimated coefficient values. They are concerned with somewhat different aspects of the problem.
A real difficulty with TLS/EIV is that it is necessary to know a priori the relative variability of the variables themselves when doing an analysis. Even then, the “residual” estimates of each are perfectly correlated. IMHO, the results in cases where the variables are also scaled to the same variance are simply unreliable particularly in the multivariate (three or more variable) case. That is part of what I meant by the term “out to lunch”.
Pingback: Live Streaming Κάλυψη Συνεδρείων
Could you condense this to questions on http://stats.stackexchange.com
to get more opinions / real examples ? EIV and TLS could be separate questions:
EIV: how to plot and measure model fit from a model of Xnoise, Ynoise ?
(Example, year-to-year climate: a date “22 August” has error 0 on a calendar scale, but +- 14 days on a lunar scale.
Is the latter EIV, if not what are “wobbly scales” called ?)
TLS: are there standard ways to scale X Y, to regularize ?
Isn’t Nullspace(A) *very* sensitive to A ? TLS success stories ?